Reporte técnico predicción número de vehículos registrados en el sistema de tránsito Nacional

Pamela Escobar Palacio1, Juan Jose Monsalve Patino2, José Julián Aguirre Ramírez3, Santiago Mejia Carmona4,
1 Estudiante de Ingeniería Administrativa, Universidad Nacional de Colombia, sede Medellín.
paescobarp@unal.edu.co
2 Estudiante de Ingeniería Industrial, Universidad Nacional de Colombia, sede Medellín.
jumonsalvep@unal.edu.co
3 Estudiante de Ingeniería Industrial, Universidad Nacional de Colombia, sede Medellín.
joaguirrer@unal.edu.co
4 Estudiante de ingeniería de sistemas, Universidad Nacional de Colombia, sede Medellín.
sanmejiacar@unal.edu.co
Reporte técnico predicción número de vehículos registrados en el sistema de tránsito Nacional
Indice
1. Introducción
2. Objetivo general
3. Objetivos específicos
4. Problema
5. Metodología de solución
6. Análisis descriptivo
7. Modelos y desempeño
8. Resultados
9. Aprendizaje
10. Bibliografía
Introducción
En el ámbito del análisis predictivo, se presenta en este informe un modelo eficiente destinado a calcular el número de vehículos registrados en el Registro Único Nacional de Tránsito (RUNT) durante el periodo comprendido entre 2012 y 2016, así como el primer semestre del 2018. Este informe adquiere una relevancia significativa, considerando que el RUNT constituye una herramienta fundamental para el control y la gestión del tránsito vehicular en Colombia.
Con el propósito de alcanzar este objetivo, se emplean técnicas de aprendizaje automático, llevando a cabo la comparación de diversos modelos para identificar y seleccionar el más eficiente en términos predictivos. Más allá de la mera anticipación del flujo vehicular, la intención subyacente en este informe es proporcionar una guía detallada y fundamentada para aquellos inmersos en el desafiante terreno del análisis predictivo aplicado al tránsito vehicular.
Objetivo general
Crear un modelo predictivo para calcular el número de vehículos registrados en el sistema de tránsito Nacional entre 2012 - 2016 y el primer semestre del 2018. Los datos para crear el modelo se encuentran en el drive del curso bajo el nombre "registro_autos_entrenamiento.xlsx".
Objetivos específicos
1. Realizar una descripción y justificación de las variables que se trataran para realizar el modelo
2. Comparar distintos modelos y realizar la predicción con el mejor de estos según sus métricas
3. Calcular las métricas de cada modelo: mse, r2, variación del mse, mae, rmse
Problema
Crear un modelo para predecir el número de vehículos registrados diariamente en el Registro Único Nacional de Tránsito (RUNT), el cual solo cuenta con dos variables: fechas y unidades de vehículos registrados, por lo tanto se debe crear más variables a partir de esto, para crear un modelo que se ajuste correctamente con los valores iniciales.
Metodología de solución
Inicialmente se realiza instalación de módulos necesarios y lectura de librerías. Se procede a hacer lectura de los datos:
datos:el cual contiene los datos de "registro_autos_entrenamiento" en excel.
festivos: tiene datos de las fechas festivas en Colombia, elaboración propia.
navidad = contiene los 24 de diciembre de cada año, presentados en excel y es elaboración propia
año_nuevo= tiene el 1 de enero de cada año en excel, es de elaboración propia.
Se agregan las variables que se pueden considerar en el modelo: año, mes, día, nombre del día, si es lunes, martes, miércoles, jueves, viernes, sábado y domingo, quincena, festivos, navidad y año nuevo.
Luego se realiza un tratamiento de los outliers con el fin de excluir los datos que puedan sesgar el modelo predictivo, para ellos se toman los outliers mayores a 1.1, para este paso se debe tener cuidado dado que dependiendo del valor de los outliers que se desean expulsar, el modelo puede quedar mejor ajustado o no. Se realiza prueba y error, para finalmente determinar cuál es el valor ideal.
Se evidencia que la mayoría de fechas que son domingos son eliminadas del modelo, esto se explica porque los domingos no es común que se trabaje en las oficinas del RUNT, por tal motivo esta variable no estaría explicando bien los datos dado a que no son días en los que se realicen registros [1].
Se realiza lectura de los datos con el fin de explicar y dar a entender el análisis descriptivo y el comportamiento de los datos (Presentes en la siguiente sección)
Para realizar la comparación de los modelos, se utiliza la función setup de la librería pycaret, la cual es útil para comparar y evaluar diferentes modelos para machine learning [2]. Para llevar a cabo cualquier modelo se identifican primero cuáles serán esas variables que utilizará para llevarlo a cabo: año, día, mes, lunes, martes, miércoles, jueves, viernes, sábado y festivos.
Del paso anterior se realiza la comparación de cada modelo y se seleccionan tres modelos: Gradient Boosting Regressor, Light Gradient Boosting Machine y Random Forest Regressor, de los cuales se estudian sus métricas de variación de mse y r2. Sin embargo el seleccionado para realizar predicciones es Gradient Boosting Regressor dado que es el que presenta menor variación mse.
Los modelos Gradient Boosting Regressor consisten en crear varios predictores en secuencia. El primer predictor usa la media de la variable Y para predecir, luego el segundo predictor explica los errores del primer predictor, el tercer predictor explica los errores del segundo predictor y así sucesivamente [3].
Pese a que este modelo fue el mejor de todos los modelos comparados, carece de explicar variables temporales de la mejor manera como lo hace la regresión Poisson, por ello se decide realizar otro modelo con regresión Poisson, el cual con una variable puede explicar el número de eventos que ocurren en un intervalo temporal o espacial de tamaño dado [4].
Teniendo el modelo seleccionado se realizan las mismas pruebas de validación, concluyendo que es un buen modelo para realizar la predicción del número de vehículos registrados en el sistema nacional de tránsito.
Se calcula la primera predicción entre 01/01/2012 y el 31/12/2016, obteniendo el primer archivo plano. Seguido de esto se verifica esta predicción que tan ajustada es con los datos reales.
Finalmente se realiza la predicción del primer semestre del 2018, obteniendo el segundo archivo plano.
Análisis descriptivo
Con el gráfico de boxplot confirmamos que en las fechas registradas es más frecuente ver una cantidad de vehículos entre 293 y 1173, los cuales están debajo del cuantil del 25% y del 75% de los datos. Se logra ver que las unidades o la cantidad de vehículos registrados entre las fechas de 2012 y 2017, puede variar desde 0 unidades hasta 3603.
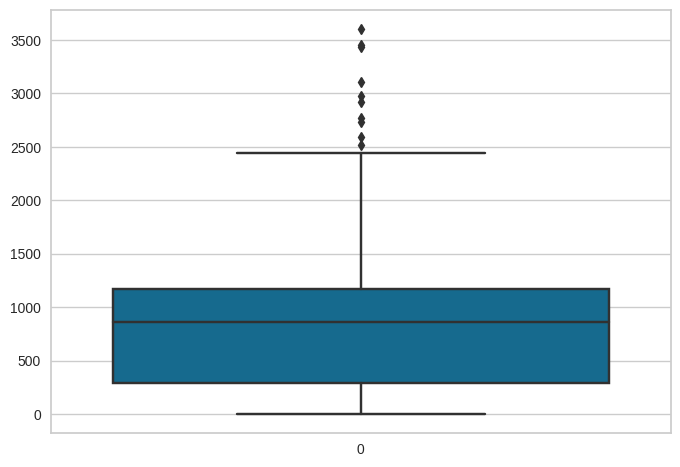
Figura 1. Boxplot número de registros en el tránsito
También se evidencia que el año que obtuvo mayor cantidad de registros realizados es el 2014, lo cual confirma lo que menciona la revista el tiempo que, 2014 sería otro año récord en ventas de carros en Colombia [5].
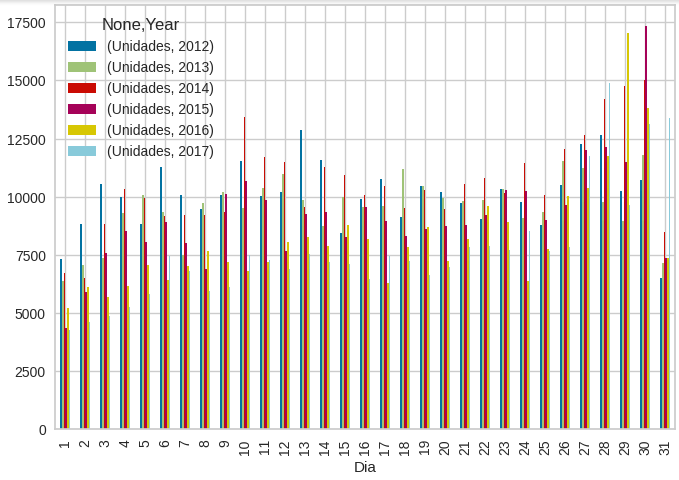
Figura 2. Cantidad de registros realizados vs días del mes
El mes con mayor cantidad de vehículos vendidos es diciembre, demostrando que el mejor mes considerado para comprar nuevos vehículos es en el último mes del año [6].
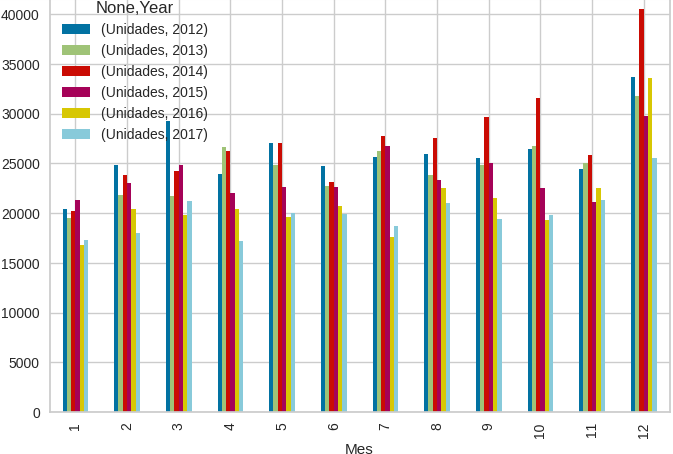
Figura 3. Cantidad de registros realizados vs meses
El día de la semana con mayor cantidad de vehículos registrados es el viernes y los días con menor cantidad de vehículos registrados son los sábados y domingos. Esto se puede deber a que los sábados en las oficinas de registros del RUNT trabajan solo hasta mediodía y los domingos no es común que lo hagan [7].
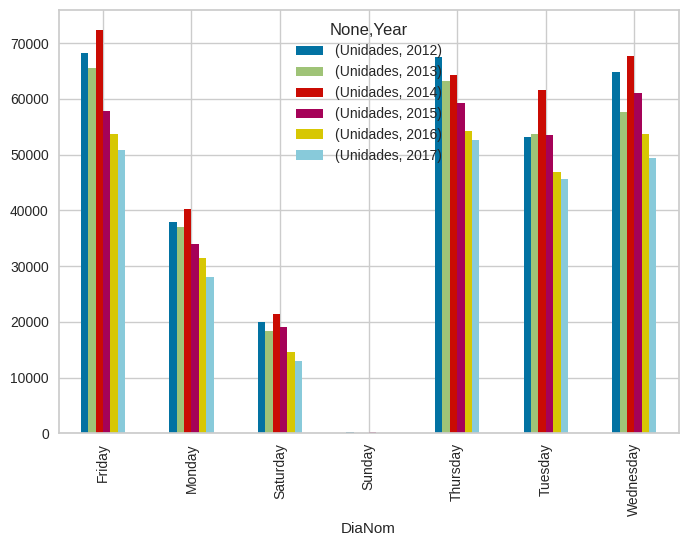
Figura 4. Cantidad de registros realizados vs día de la semana
Se incluyen igualmente los festivos entre 2012 y 2017 dado que se pueden realizar registros en estas fechas, sin embargo como se logra ver, la mayoría de registros se realizan en días no festivos, y los registros que se realizan en festivos son muy pocos, esto se puede deber igualmente al rango de tiempo de atención en esos días, los cuales pueden ser limitados [1]. Inscripción de personas ante el Registro Único Nacional de Tránsito (RUNT). (2022, enero 11). Alcaldía de Medellín. o porque son fechas especiales y las personas usualmente se dedican a otras actividades familiares, amigos y de descanso.
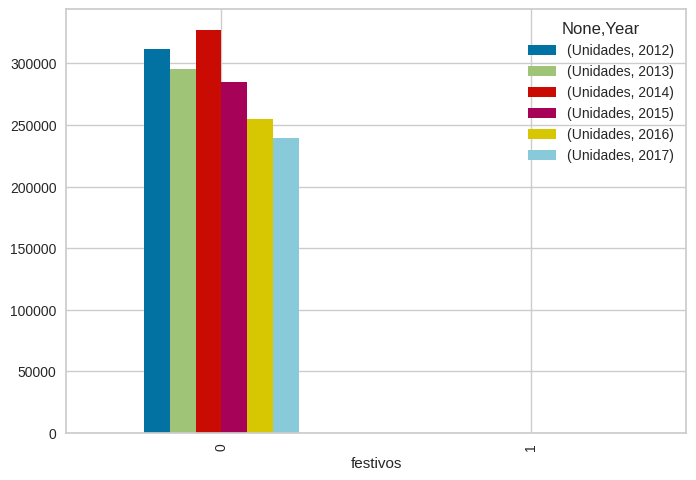
Figura 5. Cantidad de registros realizados vs festivos
Modelos y desempeño
Para medir el desempeño de un modelo se destacan dos métricas en particular: R2 y variación mse
El valor de R2 varía entre 0 y 1, y a veces puede ser negativo. Aquí hay una interpretación general de los valores que puede tomar:
R2 = 1: Perfecto. El modelo explica toda la variabilidad en la variable dependiente.
R2 = 0: El modelo no explica nada de la variabilidad en la variable dependiente.
0 < R2 < 1: El modelo explica una proporción específica de la variabilidad en la variable dependiente. Cuanto más cerca de 1, mejor.
R2 < 0: Algo está muy mal. El modelo es peor que un modelo que simplemente predice la media de la variable dependiente.
En resumen, un valor de R2 más cercano a 1 indica un mejor ajuste del modelo a los datos [8]. Aplicado en el resultado de los modelos se observa que el mejor R2 es Modelo Light Gradient Boosting Machine y de Modelo Gradient Boosting Regressor porque son los más cercanos a 1 y según la definición anterior el modelo explica una proporción específica de la variabilidad en la variable dependiente.
Por otro lado, variaciones mayores al 15% pueden indicar sobre entrenamiento o sobreajuste. En este caso el mejor modelo es aquel que se encuentra por debajo de este valor; se destacan Modelo Gradient Boosting Regressor y Modelo de regresión Poisson, sin embargo este último lo supera y se sigue considerando mejor.
Tabla 1. Modelos y métricas de desempeño
Resultados
La evaluación de los coeficientes de determinación (R^2) revela que se alcanza el rendimiento óptimo con un gradiente más pronunciado, mientras que el modelo Poisson presenta el R^2 menos favorable. Se observa una discrepancia notoria entre la varianza y la media del modelo Poisson, indicando que, en este caso específico, la adaptación de este modelo no es la mejor.
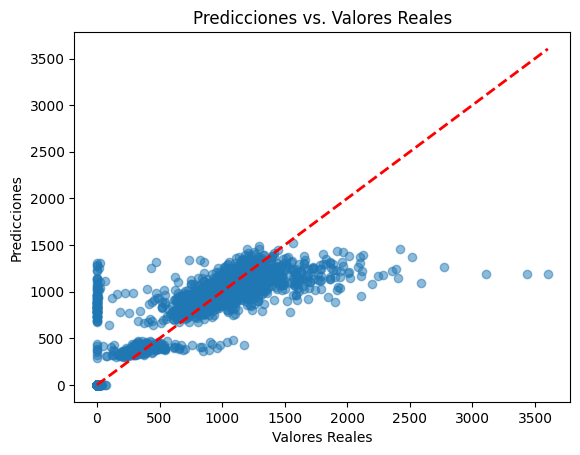
Figura 6. Valores predichos vs valores reales entre 2012 y 2016
Aprendizaje
Durante el proceso analítico, se ha constatado que el modelo Poisson ha exhibido el mejor ajuste a los datos en consideración. Este modelo, específicamente diseñado para variables de conteo, ha demostrado ser altamente apropiado para capturar la naturaleza de los eventos observados en un intervalo temporal o espacial específico. No obstante, al realizar un análisis visual de la concordancia entre los valores predichos por el modelo y los valores reales, se han identificado varios puntos atípicos en la gráfica correspondiente. Estos puntos atípicos sugieren posiblemente fenómenos inusuales o incluso errores en la recopilación de datos que requieren una evaluación más detallada. Con el objetivo de mitigar la influencia de estos puntos atípicos y mejorar la estabilidad de la inferencia estadística, se implementó el método de z-scores. Este enfoque estadístico permite la estandarización de los datos, expresando la distancia de cada observación con respecto a la media en términos de desviaciones estándar. Al establecer un umbral crítico, generalmente definido como un z-score absoluto superior a 3, se logró la identificación y tratamiento de los puntos atípicos, contribuyendo así a la robustez del análisis y reduciendo la susceptibilidad a valores extremos. Es crucial destacar que, si bien la aplicación del z-score constituye una estrategia efectiva para abordar datos atípicos, no incide directamente en la variabilidad intrínseca de los datos, es decir, la varianza. Para gestionar problemas asociados con la varianza, se sugiere explorar técnicas adicionales y considerar transformaciones de datos que aborden de manera más específica dicho aspecto. El aprendizaje de modelos automatizados revela que, a pesar de su capacidad para aprender patrones complejos, no siempre garantizan precisión absoluta. Además, es crucial reconocer su sensibilidad ante datos atípicos, ya que estos pueden ejercer una influencia significativa en la variabilidad de las predicciones. Como recomendación, se sugiere explorar la implementación de modelos más robustos, como Random Forest o Redes Neuronales Recurrentes (RNN). Estos enfoques ofrecen una mayor capacidad para lidiar con la complejidad inherente de los datos y pueden mitigar los efectos adversos de datos atípicos, mejorando así la estabilidad y la generalización del modelo. La elección entre Random Forest y RNN dependerá de la naturaleza específica de los datos y de los patrones que se pretenda capturar, ofreciendo alternativas valiosas para abordar los desafíos asociados con la sensibilidad a datos atípicos.
Bibliografía
[1] Inscripción de personas ante el Registro Único Nacional de Tránsito (RUNT). (2022, enero 11). Alcaldía de Medellín. https://www.medellin.gov.co/es/tramites-y-servicios/inscripcion-de-personas-ante-el-registro-unico-nacional-de-transito-runt/
[2] Initialize. (s/f). Gitbook.Io. Recuperado de https://pycaret.gitbook.io/docs/get-started/functions/initialize
[3] Hernández, F. (2023, septiembre 25). 7 Gradient Boost. Github.io. https://fhernanb.github.io/libro_mod_pred/gradboost.html
[4] REGRESIÓN DE POISSON. (s/f). Hrc.es. Recuperado el 1 de diciembre de 2023, de http://www.hrc.es/bioest/Poisson_1.html
[5] El Tiempo, R. (2015, enero 4). 2014 sería otro año récord en ventas de carros en Colombia. El Tiempo. https://www.eltiempo.com/archivo/documento/CMS-15052539
[6] Las mejores fechas para comprar un carro. (s/f). Carroya noticias. Recuperado el 28 de noviembre de 2023, de https://www.carroya.com/noticias/guias-de-compra-y-venta/las-mejores-fechas-para-comprar-carro-4411.
[7] Inscripción de personas ante el Registro Único Nacional de Tránsito (RUNT). (2022, enero 11). Alcaldía de Medellín. https://www.medellin.gov.co/es/tramites-y-servicios/inscripcion-de-personas-ante-el-registro-unico-nacional-de-transito-runt/
[8] Análisis de Regresión: ¿Cómo Puedo Interpretar el R-cuadrado y Evaluar la Bondad de Ajuste? (s/f). Minitab.com. Recuperado el 28 de noviembre de 2023, de https://blog.minitab.com/es/analisis-de-regresion-como-puedo-interpretar-el-r-cuadrado-y-evaluar-la-bondad-de-ajuste
Comentarios
Publicar un comentario