Reporte técnico clasificación de imágenes

Pamela Escobar Palacio1, Juan Jose Monsalve Patino2, José Julián Aguirre Ramírez3, Santiago Mejia Carmona4,
1 Estudiante de Ingeniería Administrativa, Universidad Nacional de Colombia, sede Medellín.
paescobarp@unal.edu.co
2 Estudiante de Ingeniería Industrial, Universidad Nacional de Colombia, sede Medellín.
jumonsalvep@unal.edu.co
3 Estudiante de Ingeniería Industrial, Universidad Nacional de Colombia, sede Medellín.
joaguirrer@unal.edu.co
4 Estudiante de ingeniería de sistemas, Universidad Nacional de Colombia, sede Medellín.
sanmejiacar@unal.edu.co
Reporte técnico clasificación de imágenes
Índice
Introducción
Objetivo general
Definición del problema
Metodología de solución
Análisis descriptivo
Modelos y desempeño
Aprendizaje
Repositorio
Bibliografía
Introducción
En la era actual, la capacidad de analizar y comprender datos visuales es esencial en diversas aplicaciones, desde la seguridad hasta la identificación de patrones de comportamiento. En este contexto, el presente trabajo se centra en el análisis de imágenes de personas, específicamente diferenciando entre aquellas que utilizan gafas y las que no las utilizan. Este tipo de clasificación tiene aplicaciones prácticas en la identificación de individuos, sistemas de seguridad y análisis de comportamientos visuales. En resumen, este trabajo aborda la tarea específica de clasificación de imágenes de personas con y sin gafas, utilizando técnicas de aprendizaje estadístico, con la aspiración de ofrecer una contribución valiosa al campo del análisis de imágenes y reconocimiento visual.
Objetivo general
Desarrollar un modelo predictivo que pueda analizar las imágenes y predecir si el sujeto lleva gafas o no. Esto implica la clasificación binaria de las imágenes en dos categorías: "con gafas" y "sin gafas". Se espera que el modelo pueda generalizar correctamente a nuevas imágenes no vistas durante el entrenamiento.
Definición del problema
En el contexto del conjunto de datos CMU Face Images Data Set del UCI Machine Learning Repository [1], se presenta el desafío de construir y validar un modelo de aprendizaje estadístico capaz de clasificar imágenes de sujetos según la presencia o ausencia de gafas.
El conjunto de datos consta de 640 imágenes que representan a diversos sujetos en diferentes posiciones y expresiones faciales. Cada imagen está etiquetada con información detallada, incluyendo la identificación del usuario, la posición de la cabeza, la expresión facial, el estado de los ojos (gafas o no) y la escala de la imagen.
La identificación precisa de personas con gafas y sin ellas es un desafío fundamental en sistemas de reconocimiento visual. La variabilidad en las expresiones faciales y las condiciones de iluminación hace que este problema sea especialmente complejo. La motivación detrás de este trabajo radica en desarrollar un modelo capaz de realizar esta clasificación con un alto grado de precisión, utilizando técnicas de aprendizaje estadístico.
Metodología de solución

El conjunto de datos incluye estas imágenes <userid> <pose> <expression> <eyes> <scale>.pgm
<userid> , el cual es la identificación del usuario de la persona en la imagen, y este campo tiene 20 valores: an2i, at33, boland, bpm, ch4f, cheyer, choon, danieln, glickman, karyadi, kawamura, kk49, megak, mitchell, night, phoebe, saavik, steffi, sz24 y tammo.
<pose> Es la posición de la cabeza de la persona, y este campo tiene 4 valores: straight (recto), left (izquierda), right (derecha), up (arriba).
<expression> Es la expresión facial de la persona, y este campo tiene 4 valores: neutral, happy (feliz), sad (triste), angry (enojado).
<eyes> Es el estado de los ojos de la persona, y este campo tiene 2 valores: open (abiertos), sunglasses (gafas de sol).
<scale> Es la escala de la imagen, y este campo tiene 3 valores: 1, 2 y 4; 1 indica una imagen de resolución completa (128 columnas por 120 filas); 2 indica una imagen de resolución media (64 por 60); 4 indica una imagen de resolución cuarto (32 por 30).
Se importan las librerías necesarias como TensorFlow, Keras, scikit-learn, y otras para el procesamiento de datos [2], manipulación de imágenes, construcción y entrenamiento del modelo, así como para la visualización de resultados. Por consiguiente se realiza un análisis descriptivo y exploratorio del conjunto de datos, mostrando el número de imágenes con y sin gafas, del cual se obtiene que se cuentan con 312 sin gafas y 313 con gafas. Al cargar las imágenes del conjunto de datos, se les aplica un preprocesamiento (ajuste de tamaño) y se dividen en conjuntos de entrenamiento y prueba.
Se visualizan algunas imágenes de las clases "con gafas" y "sin gafas" para comprender mejor el conjunto de datos, la cual se muestra en la figura 1.

Figura 1. Imágenes de las clases "con gafas" y "sin gafas"
Posterior a esto, se construye un modelo de red neuronal utilizando Keras. El modelo tiene una capa de entrada, una capa oculta con activación ReLU y una capa de salida con activación sigmoide. Se utiliza la función de pérdida de entropía cruzada binaria y el optimizador Adam para entrenar el modelo[3].
Para realizar las pruebas del modelo se realizan predicciones en el conjunto de prueba y se evalúa el rendimiento del modelo utilizando métricas como la precisión, el recall y el F1-score, obteniendo una precisión de 0.808 y los siguientes resultados presentados en la tabla 1 y 2.
Tabla 1. Informe de clasificación
Tabla 2. Informe promedios macro y ponderado
|
|
precision |
recall |
f1-score |
support |
|
accuracy |
0.81 |
125 |
||
|
macro avg |
0.81 |
0.80 |
0.80 |
125 |
|
weighted avg |
0.81 |
0.81 |
0.81 |
125 |
Se realiza el cálculo de métricas adicionales como precisión, recall, F1-score y el área bajo la curva ROC, y se obtiene que:
Precisión:
0.8125
Recall:
0.7222222222222222
F1-score:
0.7647058823529411
Área bajo la curva ROC: 0.9003651538862807
Finalmente
se visualizan gráficas de la matriz de confusión (figura 2), las curvas de
precisión-recall (figura 3) y curva ROC (figura 4) para proporcionar una
representación gráfica del rendimiento del modelo.
Análisis descriptivo
Si has estado observando de cerca en los directorios de imágenes, podrías notar que algunas imágenes tienen el sufijo .bad en lugar del sufijo .pgm. Resulta que 16 de las 640 imágenes tomadas tienen fallas debido a problemas con la configuración de la cámara; estas son las imágenes .bad. Algunas personas tuvieron más problemas que otras, pero todos los que fueron "faced" deberían tener al menos 28 buenas imágenes faciales (de las 32 variaciones posibles, excluyendo la escala).
En la sección de entrenamiento del modelo, entendemos que la pérdida es una medida de cuánto el modelo está equivocándose durante el entrenamiento. En la primera parada, la pérdida de entrenamiento es alta (7.54), lo que indica que el modelo inicialmente tiene dificultades para ajustarse a los datos. A medida que avanza el entrenamiento, la pérdida disminuye progresivamente, alcanzando valores más bajos en las épocas posteriores. Esto sugiere que el modelo está mejorando su capacidad para hacer predicciones correctas en el conjunto de entrenamiento.
La precisión representa la fracción de instancias correctamente clasificadas. Al inicio, la precisión es del 51.10%, indicando que el modelo está clasificando correctamente aproximadamente la mitad del conjunto de entrenamiento. La precisión mejora a medida que el modelo se entrena, alcanzando un 78.96% en la última época. Esto sugiere que el modelo ha aprendido patrones en los datos y es capaz de realizar clasificaciones más precisas.
La pérdida y la precisión en el conjunto de validación (val_loss y val_accuracy) proporcionan una indicación de cómo generaliza el modelo a datos no vistos. En general, se observa una mejora y estabilización en la precisión de validación a medida que el modelo se entrena.
Cada época representa una iteración completa a través de todo el conjunto de entrenamiento. El tiempo de entrenamiento por época varía, pero en general, se observa que el modelo converge a resultados significativos en un número relativamente bajo de épocas.
En las pruebas del modelo también, se identifica que el valor de accuracy, el cual es de 0.808, nos indica que el modelo clasifica correctamente aproximadamente el 80.8% de las instancias en el conjunto de prueba. Esta métrica es una medida general del rendimiento del modelo y sugiere que el modelo está acertando en la clasificación en una proporción considerable de casos. De las tablas 1 y 2 se dara interpretacion de los resultados obtenidos:
Clase 0 (Sin Gafas)
Una Precisión de 0.81, representa que del total de instancias clasificadas como "sin gafas", el 81% realmente pertenece a esa clase. El Recall de 0.87 del total de instancias que realmente son "sin gafas", el modelo logra identificar correctamente el 87%. Un F1-score de 0.84, es una medida ponderada de precisión y recall, proporcionando una visión general del rendimiento. Un valor de 0.84 indica un equilibrio entre precisión y recall para la clase "sin gafas".Un Support de 71, representa el número total de instancias de la clase "sin gafas" en el conjunto de prueba.
Clase 1 (Con Gafas)
Una precisión de 0.81 del total de instancias clasificadas como "con gafas", el 81% realmente pertenece a esta clase.El Recall de 0.72, significa que del total de instancias que realmente son "con gafas", el modelo logra identificar correctamente el 72%. Un F1-score de 0.76 indica un equilibrio entre precisión y recall para la clase "con gafas". y luego el Support de 54 representa el número total de instancias de la clase "con gafas" en el conjunto de prueba.
El modelo presenta un rendimiento consistente en todas las métricas, con una precisión global del 81%. Tanto el promedio macro como el promedio ponderado indican un equilibrio razonable en la capacidad del modelo para clasificar imágenes de personas con y sin gafas. En conjunto, estos resultados presentados en la sección de pruebas del modelo, sugieren que el modelo es capaz de realizar clasificaciones precisas en ambas clases, y los promedios macro y ponderados ofrecen una evaluación más completa teniendo en cuenta la distribución de clases en el conjunto de prueba.
Modelos y desempeño
El modelo que estás utilizando en este código es una red neuronal construida utilizando la biblioteca Keras, que es una interfaz de alto nivel para TensorFlow[5]. Este modelo es una red neuronal con las siguientes capas:
model = models.Sequential([layers.Dense(4096, activation='relu', input_shape=(64*64*3,)),
layers.Dropout(0.5), layers.Dense(1, activation='sigmoid')])
La capa de entrada tiene 4096 neuronas (nodos) con una función de activación ReLU (Rectified Linear Unit). La entrada tiene la forma de un vector aplanado de tamaño 64x64x3. La capa de dropout tiene una tasa de abandono (dropout rate) del 50%, lo que significa que durante el entrenamiento, la mitad de las neuronas se desactivarán aleatoriamente en cada paso para evitar el sobreajuste, finalmente la capa de salida tiene una sola neurona con una función de activación sigmoide. Dado que es un problema de clasificación binaria (con gafas o sin gafas), la función sigmoide se utiliza para producir una salida en el rango de 0 a 1 [5], interpretada como la probabilidad de pertenecer a la clase positiva.
El modelo se compila utilizando el optimizador 'adam' y la función de pérdida 'binary_crossentropy'. Luego se entrena el modelo utilizando el conjunto de entrenamiento (X_train, y_train) durante 10 épocas. La métrica de evaluación principal durante el entrenamiento es la precisión (accuracy), del cual se obtiene una precisión de 0.8125, como se mencionó anteriormente.
En términos de las capacidades de clasificación y errores específicos del modelo se puede decir que, en la figura 2, se puede concluir que hay 39 instancias correctamente clasificadas como "Con Gafas". Hay 62 Instancias correctamente clasificadas como "Sin Gafas". Estas son imágenes de personas con y sin gafas que el modelo identificó correctamente. Hay 9 Instancias incorrectamente clasificadas como "Con Gafas". Estas son imágenes de personas sin gafas que el modelo clasificó erróneamente como si llevaran gafas.Luego tenemos que hay 15 Instancias incorrectamente clasificadas como "Sin Gafas". Estas son imágenes de personas con gafas que el modelo clasificó erróneamente como si no llevan gafas.
De la figura 3, se entiende que el valor del área bajo la curva mientras más cercano a 1 sea, significa que el modelo tiene un rendimiento fuerte en términos de precisión y recall [6]. En este caso tenemos un valor de 0.88 el cual es cercano a 1, el cual cuantifica la capacidad del modelo para clasificar positivos con alta precisión y alto recall. Similar a la anterior gráfica tenemos la figura 3, la curva ROC, la cual explica que con Un valor cercano a 1 indica un buen rendimiento, en este caso se obtiene 0,90 el cual se acerca bastante a 1.
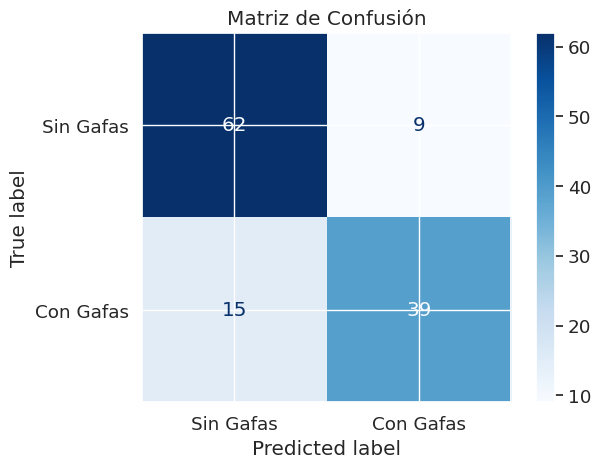
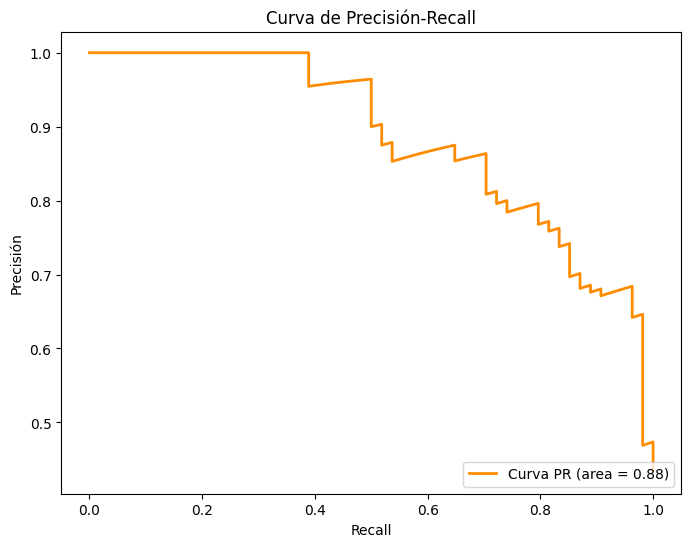
Figura 2. Matriz de confusión Figura 3. Curva de precisión-recall
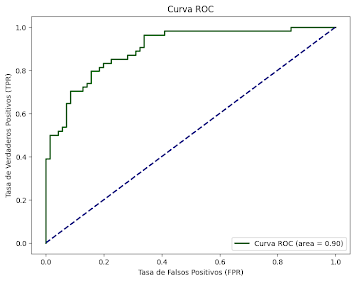
Figura 4. Curva ROC
Finalmente, después de crear el modelo, validarlo, demostrar que tiene buenas métricas, entrenarlo con todos los datos, se realiza una validación con algunas imágenes del dataset en la sección de Predicción del código adjuntado (imagenes.ipynb), de lo cual se puede concluir que el modelo realiza buenas predicciones de las imágenes que lee del dataset, determinando si tienen gafas o no.
Aprendizaje
A
partir de los resultados obtenidos y de la exploración de las imágenes, el
modelo muestra un rendimiento sólido en términos de métricas de evaluación,
indicando su capacidad para clasificar imágenes de personas con y sin gafas con
una precisión razonable; se identificó que la elección de la arquitectura de la
red, el tamaño de las imágenes y otros parámetros es crucial y puede afectar
significativamente el rendimiento del modelo, por tal razón es que la
evaluación detallada, el entrenamiento con todos los datos, incluyendo la
visualización de resultados y métricas específicas, proporciona información
valiosa sobre el rendimiento y posibles áreas de mejora para el modelo.
Repositorio
9.
Bibliografía
[3] La función sigmoide. (s/f). Interactivechaos.com. Recuperado de https://interactivechaos.com/es/manual/tutorial-de-machine-learning/la-funcion-sigmoide
Comentarios
Publicar un comentario